两篇LLM入门文章的一些学习和总结.
date
Apr 4, 2023
AISummary
AI translation
slug
4-paper
status
Published
tags
ChatGPT
AI
Paper
type
Post
Authors
Published
Published
1.GPT-4 Technical Report
这篇Technical Report其实之前就看了,但是并没有做笔记.于是决定重新整理一下笔记并重新学习一下.
具体用到的东西还是之前提到的https://typeset.io/,就不多做描述了.
本文描述了 GPT-4 的开发,这是一种大规模的多模式模型,可以接受图像和文本输入并生成文本输出。该模型经过预先训练,可以预测文档中的下一个Token,并通过利用人工反馈进行微调的过程与人类意图保持一致。作者报告说,GPT-4 在各种专业和学术基准上表现出人类水平的表现,包括通过模拟律师资格考试,分数约为应试者前 10%。本文还讨论了基础设施和优化方法的开发,这些方法在各种规模上均具有可预测的表现。
说白了这篇文章就是GPT4的一份说明书,GPT4已经在各项测试中彻底的击败了以前的语言模型,水平到了一个非常恐怖的地步(超过90%的人类).
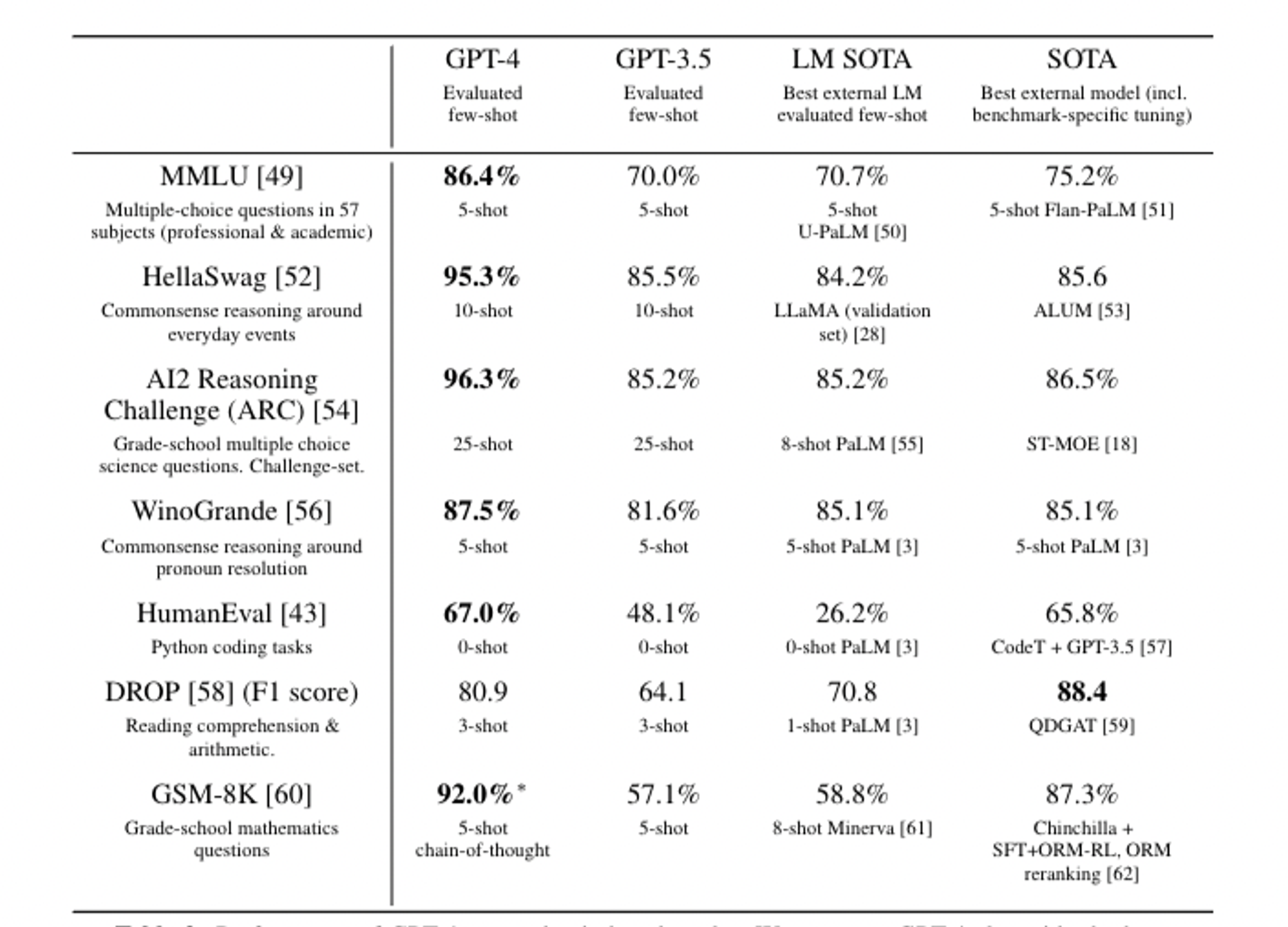
值得注意的点是,GPT4的多语言能力也获得了极大的提高.
但是我比较在意的是目前GPT还没有开放的多模能力。因为GPT4如果具有多模能力的话,那么说明训练的内容会不止是文字,还有图片,视频,这其实是一件非常恐怖的事。想象一下一个有着人类平均智力的个体看过所有的人类的文字,图片,视频,并且能够精准的进行分类与信息定位,并且一个月的工资只要20$? 无法想象这样的未来。掌握AI能力的人,一定会成为超级个体。
之前有不少人想基于GPT+Gen2来做视频自动剪辑,但是如果GPT4真的开放了多模态能力,那这个点子估计还没做出来就暴死了。GPT4也基本彻底杀死了NLP。
而且其实文章里也很清晰的描述了,GPT-4还是一个早期型号。很多人惊呼GPT-3.5可能是AI的“iphone4时刻”,但是也许不是?GPT-4可能只是Iphone2。
另外一个令人在意的点是,GPT-4居然出现了Power Seeking的行为…它会自发的想要找算力来提升自己。这已经不是一个正常的行为了吧。
不管怎么说,令人恐惧。
2.Lora - Low-Rank Adaptation of Large Language Models.
Lora的重要性真是怎么吹都不为过的.
本文讨论了自然语言处理中的一种范例,在这种模式下,对一般域数据进行大规模预训练,然后适应特定的任务或领域。但是,随着预训练的模型变得越来越大,由于大量可训练的参数,完全微调变得不可行。为了解决这个问题,本文提出了一种名为Low-Rank Adaption(LoRa)的方法,该方法冻结了预训练的模型权重,并将可训练的等级分解矩阵注入Transformer架构的每一层,从而大大减少了下游任务的可训练参数的数量。尽管可训练参数更少、训练吞吐量更高且没有额外的推理延迟,但LoRa在各种语言模型上的模型质量的表现与微调相当,甚至更好。该论文还对语言模型适应中的排名不足进行了实证研究,这揭示了LoRa的功效。
Lora最牛逼的地方在于以前高不可攀的大模型预训练现在人人都可以做了,之前就连GPT-3的fine tune都会需要不少的真金白银,但是Lora不用.参数减少1W倍,内存减少3倍的效果是立竿见影的.
其实这也是我买4090机器的一手助推吧,毕竟基于GPT4的API批量生成语料做Lora再用一些低Rank的模型自用,想想都觉得很靠谱.我们大部分的场景并不需要这么强大的GPT4,只需要在专业领域甚至专有业务领域可以做到某些事的特定模型,那用GPT-4生成资料再用6B一类的模型学习后本地部署就明显是当前最优方案了.
其实这些东西的门槛真的不是很高,但是整套工具链的整合和产生我觉得是一个极佳的机会,也是值得砸精力进去的地方.Lora的论文倒是信息量不是很大,只是具体的方式和原理确实值得研究一下.
先不说别的,在AI里砸入1000h的高质量时间,再谈收获吧.